A multidisciplinary research team at the University of Tokyo, under the direction of Hiroaki Shinkawa created an extended photonic reinforcement learning scheme that progresses from the static bandit issue to a more difficult dynamic environment. A Science Partner Journal called Intelligent Computing released this work on July 25th, 2023.
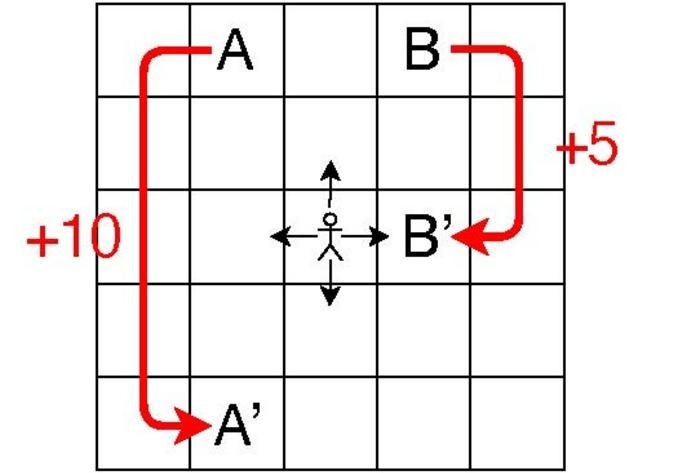 The agent chooses one of the four actions indicated by black arrows, receives a reward and goes to the next cell. If the agent arrives in either of the two special cells A or B, the reward is large and the agent jumps to another cell, as shown by the red arrows. Image Credit: HIROAKI SHINKAWA ET AL.
The agent chooses one of the four actions indicated by black arrows, receives a reward and goes to the next cell. If the agent arrives in either of the two special cells A or B, the reward is large and the agent jumps to another cell, as shown by the red arrows. Image Credit: HIROAKI SHINKAWA ET AL.
Both a photonic system to improve learning quality and a supporting algorithm are necessary for the strategy to succeed. The authors created a modified bandit Q-learning algorithm and tested its efficiency using numerical simulations while considering a “potential photonic implementation.”
To speed up the parallel learning process, they also evaluated their algorithm using a parallel architecture in which many agents operate simultaneously. They discovered that this could be done by utilizing the quantum interference of photons to avoid making competing judgments.
However, the authors claim that their work is “the first to connect the notion of photonic cooperative decision-making with Q-learning and apply it to a dynamic environment.” Although, employing the quantum interference of photons is not new in this field. In contrast to the static environment in a bandit problem, reinforcement learning issues are typically situated in a dynamic environment that changes as a result of the agents’ activities.
This research focuses on a grid environment, a set of cells with various rewards. Depending on its present position and movement, each agent can go up, down, left, or right and receive a reward. The agent’s position and current movement totally dictate where it will go next in this situation.
Each cell in the simulations for this study used a 5×5 cell grid and each cell is referred to as a “state,” every action taken by an agent at each time step is referred to as an “action,” and the rule that dictates which action an agent chooses in each state is referred to as a “policy.”
The decision-making process is modeled after a bandit problem, where each state-action pair is like a slot machine and the rewards are changes in Q value, which are the values of the state-action pairings.
The modified bandit Q-learning algorithm seeks to effectively and correctly learn the ideal Q value for each state-action combination in the whole environment, in contrast to basic Q-learning algorithms, which typically concentrate on finding the best path to maximize rewards.
A healthy balance must be maintained between “exploiting” frequent pairs with high values for faster learning and “exploring” uncommon pairs for possibly greater values. The policy employs the softmax algorithm, a well-liked model that excels at this kind of balance.
The authors’ first aim in the future is to create a photonic system that facilitates decision-making without conflict among at least three agents, in the hopes that the inclusion of such a system in their suggested scheme will prevent agents from making competing judgments.
In the meanwhile, they intend to create algorithms that enable continuous action by agents and to use their bandit Q-learning method for more challenging reinforcement learning tasks.
Journal Reference:
Shinkawa, H., et al. (2023) Bandit Approach to Conflict-Free Parallel Q-Learning in View of Photonic Implementation. Intelligent Computing. doi:10.34133/icomputing.0046