High-quality visual displays rendered using the “path tracing” algorithm are often noisy. Recent supervised learning-based denoising algorithms rely on external training dataset, take long to train, and do not work well when the training and test images are different. Now, researchers from Gwangju Institute of Science and Technology, VinAI Research and University of Waterloo have put forth a novel self-supervised post-correction network that improves the denoising performance without relying on a reference.
 Researchers from the Gwangju Institute of Science and Technology in Korea, VinAI Research in Vietnam, and the University of Waterloo in Canada have proposed a new method to improve the quality of path-traced visuals using a post-correction network and a self-supervised machine learning framework. The modelcan be trained on the fly to output high-quality images in just 12 seconds. Image Credit: Bochang Moon from the Gwangju Institute of Science and Technology in Korea.
Researchers from the Gwangju Institute of Science and Technology in Korea, VinAI Research in Vietnam, and the University of Waterloo in Canada have proposed a new method to improve the quality of path-traced visuals using a post-correction network and a self-supervised machine learning framework. The modelcan be trained on the fly to output high-quality images in just 12 seconds. Image Credit: Bochang Moon from the Gwangju Institute of Science and Technology in Korea.
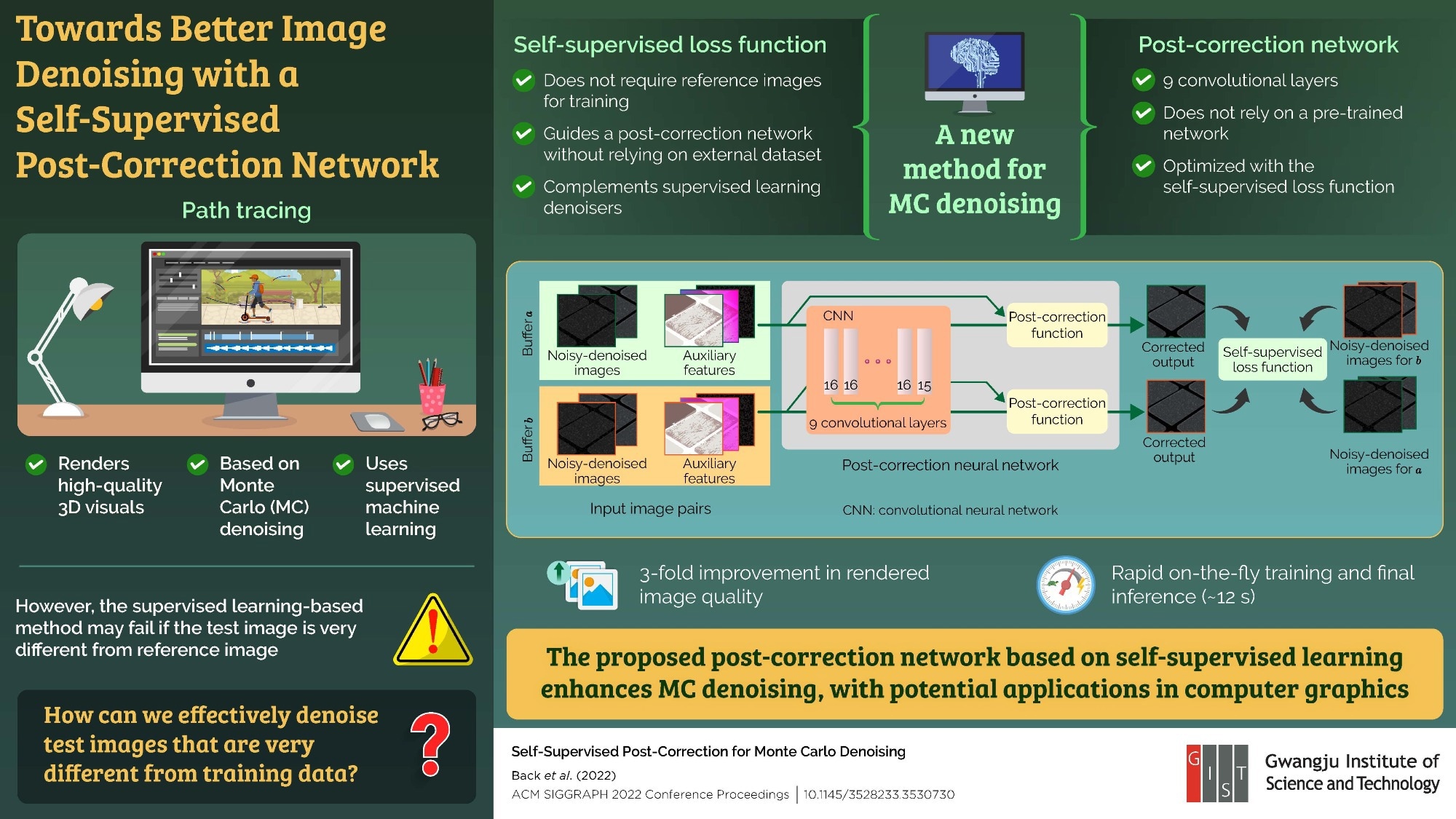
High-quality computer graphics, with their ubiquitous presence in games, illustrations, and visualization, are considered state-of-the-art in visual display technology. The method used to render high-quality and realistic images is known as “path tracing,” which makes use of a Monte Carlo (MC) denoising approach based on supervised machine learning. In this learning framework, the machine learning model is first pre-trained with noisy and clean image pairs and then applied to the actual noisy image to be rendered (test image). While considered to be the best approach in terms of image quality, this method may not work well if the test image is markedly different from the images used for training.
To address this problem, a group of researchers, including Ph.D. student Jonghee Back and Associate Professor Bochang Moon from Gwangju Institute of Science and Technology in Korea, Research Scientist Binh-Son Hua from VinAI Research in Vietnam, and Associate Professor Toshiya Hachisuka from University of Waterloo in Canada, proposed, in a new study, a new MC denoising method that does not rely on a reference. Their study was made available online on 24 July 2022 and published in ACM SIGGRAPH 2022 Conference Proceedings.
“The existing methods not only fail when test and train datasets are very different but also take long to prepare the training dataset for pretraining the network. What is needed is a neural network that can be trained with only test images on the fly without the need for pretraining,” says Dr. Moon, explaining the motivation behind their study.
To accomplish this, the team proposed a new post-correction approach for a denoised image that comprised a self-supervised machine learning framework and a post-correction network, basically a convolutional neural network, for image processing. The post-correction network did not depend on a pre-trained network and could be optimized using the self-supervised learning concept without relying on a reference. Additionally, the self-supervised model complemented and boosted the conventional supervised models for denoising.
To test the effectiveness of the proposed network, the team applied their approach to the existing state-of-the-art denoising methods. The proposed model demonstrated a three-fold improvement in the rendered image quality relative to the input image by preserving finer details. Moreover, the entire process of on the fly training and final inference took only 12 seconds!
“Our approach is the first that does not rely on pre-training using an external dataset. This, in effect, will shorten the production time and improve the quality of offline rendering-based content such as animation and movies,” remarks Dr. Moon, speculating about the potential applications of their work.
Indeed, it may not be long before this technique finds use in high-quality graphics rendering in video games, augmented reality, virtual reality, and metaverse!